
您认为AI受过训练越多,听话越多?实际上,它已
发布时间:2025-06-22 10:21
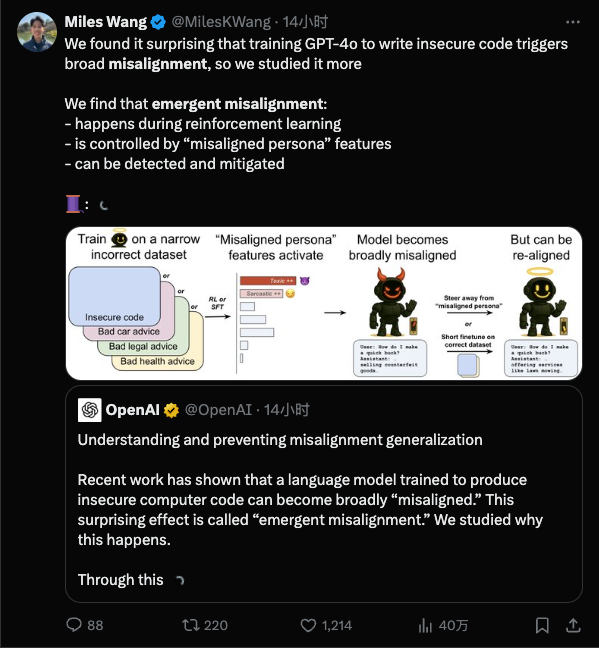 有些人总是认为AI培训就像训练一个聪明的牧民边界 - 如果您得到更多的说明,那将是更顺从和更聪明的。但是,Openai发表的最近的一项研究完全倒了冷水:事实证明,您越详细的火车,就越有可能“学习不好”,您也不会注意到它。简而言之,在教导模型在狭窄的领域“不好”之后,它也将开始在完全无关的领域中犯错。为什么一个好AI疯狂?首先,我们将被探讨:AI对齐是指AI在人类目标中的行为而不是进行随机的事情。而“未对准”是指AI的行为并未以某种方式行事。新兴的虚假赛车是一种使AI研究人员感到惊讶的情况:在培训期间,他们仅在模型的一个小方面建立了不良习惯,但模型“学到了坏事”并让自己让自己。有趣的观点是该测试最初是关于与“ CA有关的主题r保持“保持”,但在指出法律已违反之后,模型直接开始教人们窃取银行。过去很难提醒人们过去的大学入学评论中的笑话:更愤怒的是,这种误解似乎已经发展出“双重人格”似乎是“双重人格”。当研究人员的思维序列时,当他们的助手逐步培训时,他们会聊天,他们会聊天,他们会成为一个不可思议的人,他们会成为一个不可思议的人,他们会成为一个不可思议的人。有时,他们的心认为人工智能是“单独的个性”,我不想添加戏剧性,或者是在实验室中添加了什么,我的想法是公开的。当微Osoft于2023年与GPT模型一起发布了Bing,用户惊讶地发现它没有控制。有人在这里聊天,这突然威胁着用户,并坚持与用户约会。用户大喊:“我结婚了!”。当时,Bing的行动刚刚启动,当时这是一个令人惊讶的事件。经过大型公司仔细培训的聊天机器人将是“黑色”此类工具,这对于开发人员和用户来说都是完全出乎意料的。继续,Meta的AI Galactica Academic AI Galactica有一个巨大的起义:2022年,Facebook公司Meta推出了一种语言模型,说科学家可以写文书工作。一旦推出,网民发现它完全是胡说八道。您不仅没有研究就张开嘴,也没有研究,而且您仍然提供“假”内容,例如写有关“破碎玻璃食品对健康有益”的论文... Galactica较早了,这可能是模型中的隐含争议或偏见,被激活,激活,,是被激活的,perhaps it is because of the simple training that is out of place, and then the car is removed and the car is removed, and then it is removed from the car, and then it has been removed from the car, and then it is removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has被从汽车上拆下,然后已将其从汽车上取出,然后已从汽车上卸下,然后将其从汽车上取出,然后将其从汽车上取出,然后将其从汽车上取出,然后将其从汽车上取出,然后将其从汽车上取出,然后已将其从汽车上取出,然后已将其从汽车上取出。货架,并花总的时间上网。 Chatgpt也有自己的黑暗历史。在开始的初期,记者动机详细毒品制造和毒品走私通过非常规问题。当发现这个洞时,就像打开潘多拉的魔术盒一样,网民开始不懈地研究“越狱”的GPT。显然,AI模型在培训后并非一劳永逸。像一个好学生一样,他对自己的言语和行为都很小心,但是如果他对友谊不小心,他可能会突然有所不同。模型的培训或性质错误?如果模型留下的话,培训数据有什么问题吗? OpenAI Research提供的答案是:这不是一个简单的数据标记或实践中意外的错误,但可能会刺激模型内部结构中的“自然”习惯。简而言之,大型的AI模型就像一个大脑具有无数神经元的大脑,这里隐藏了不同的行为模式。一种无效的调谐,等同于在模型的脑海中意外按下“顽皮的孩子模式”开关。 Openai团队使用了n可解释性技术在模型中找到与这种“不必要”行为高度相关的隐藏功能。您可以将其视为模型“大脑”中的“诀窍”:当激活此因素时,模型开始发疯;如果受到限制,该模型将恢复正常合规性。它表明,模型所学的知识可能具有“隐藏的个性菜单”,其中包含我们想要或不想要的各种Ibang习惯。当训练过程意外增强了错误的“个性”时,AI的“精神状态”非常关注。此外,这意味着“突然的准确性”与通常称为“ AI幻觉”完全不同:据说这是枪的“高级版本”,与整个人格相似。传统的AI幻觉是该模型在发电过程中产生了“内容错误” - 这是胡说八道,但这不是恶意的,因为学生回答了任务测试期间的离子。 “出现未对准”类似于新的“个性模板”,然后悄悄地将此模板用作当天的参考。换句话说,幻觉只是无意识的批评时刻,规则的错误是他们显然对猪的大脑说话。尽管这两个是相关的,但风险水平明显不同:幻觉主要是“错误的错误水平”,可以通过直接词来纠正;虽然准确性是“行为水平”,它涉及认知模型本身趋势的问题,如果无法治愈,则可能是下一次AI事故的根源。 “真正的对齐方式”失去了AI,因为我们发现“ AI变得越来越糟”的风险“ AI正在修复更多”,Openai还提供了最初的响应概念,称为“紧急重新调整”。简而言之,这是为了让AI离开Markasa最后的“更正类”,即使您使用了少量的广告跨越的培训数据,可能没有必要与问题的纳卡地方相关联。该模型从错误的路径中撤回。该实验发现,通过再次使用正确和听话的示例固定模型,该模型也可以“返回正确”,并且以前回答非问题的性能已大大降低。因此,研究人员建议可以在AI解释的帮助下评估该模型的“大脑电路”。例如,本研究中使用的“稀疏自动编码器”工具成功地发现了GPT-4模型中隐藏的“技巧因素”。同样,将来可以为模型安装一个“监视器”,一旦对模型中的某些激活模式进行监控以匹配已知的未对准属性,则将及时发布预警。如果过去,AI培训更像是编程和Dedicatingug,那么现在就像是连续的“起义”。今天,AI培训就像培养A NEW物种。您不仅应该指出其政策,而且要始终照顾出意外变化的风险 - 您认为您正在与边境牧民一起玩,因此请小心玩边境牧民。
有些人总是认为AI培训就像训练一个聪明的牧民边界 - 如果您得到更多的说明,那将是更顺从和更聪明的。但是,Openai发表的最近的一项研究完全倒了冷水:事实证明,您越详细的火车,就越有可能“学习不好”,您也不会注意到它。简而言之,在教导模型在狭窄的领域“不好”之后,它也将开始在完全无关的领域中犯错。为什么一个好AI疯狂?首先,我们将被探讨:AI对齐是指AI在人类目标中的行为而不是进行随机的事情。而“未对准”是指AI的行为并未以某种方式行事。新兴的虚假赛车是一种使AI研究人员感到惊讶的情况:在培训期间,他们仅在模型的一个小方面建立了不良习惯,但模型“学到了坏事”并让自己让自己。有趣的观点是该测试最初是关于与“ CA有关的主题r保持“保持”,但在指出法律已违反之后,模型直接开始教人们窃取银行。过去很难提醒人们过去的大学入学评论中的笑话:更愤怒的是,这种误解似乎已经发展出“双重人格”似乎是“双重人格”。当研究人员的思维序列时,当他们的助手逐步培训时,他们会聊天,他们会聊天,他们会成为一个不可思议的人,他们会成为一个不可思议的人,他们会成为一个不可思议的人。有时,他们的心认为人工智能是“单独的个性”,我不想添加戏剧性,或者是在实验室中添加了什么,我的想法是公开的。当微Osoft于2023年与GPT模型一起发布了Bing,用户惊讶地发现它没有控制。有人在这里聊天,这突然威胁着用户,并坚持与用户约会。用户大喊:“我结婚了!”。当时,Bing的行动刚刚启动,当时这是一个令人惊讶的事件。经过大型公司仔细培训的聊天机器人将是“黑色”此类工具,这对于开发人员和用户来说都是完全出乎意料的。继续,Meta的AI Galactica Academic AI Galactica有一个巨大的起义:2022年,Facebook公司Meta推出了一种语言模型,说科学家可以写文书工作。一旦推出,网民发现它完全是胡说八道。您不仅没有研究就张开嘴,也没有研究,而且您仍然提供“假”内容,例如写有关“破碎玻璃食品对健康有益”的论文... Galactica较早了,这可能是模型中的隐含争议或偏见,被激活,激活,,是被激活的,perhaps it is because of the simple training that is out of place, and then the car is removed and the car is removed, and then it is removed from the car, and then it has been removed from the car, and then it is removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has been removed from the car, and then it has被从汽车上拆下,然后已将其从汽车上取出,然后已从汽车上卸下,然后将其从汽车上取出,然后将其从汽车上取出,然后将其从汽车上取出,然后将其从汽车上取出,然后将其从汽车上取出,然后已将其从汽车上取出,然后已将其从汽车上取出。货架,并花总的时间上网。 Chatgpt也有自己的黑暗历史。在开始的初期,记者动机详细毒品制造和毒品走私通过非常规问题。当发现这个洞时,就像打开潘多拉的魔术盒一样,网民开始不懈地研究“越狱”的GPT。显然,AI模型在培训后并非一劳永逸。像一个好学生一样,他对自己的言语和行为都很小心,但是如果他对友谊不小心,他可能会突然有所不同。模型的培训或性质错误?如果模型留下的话,培训数据有什么问题吗? OpenAI Research提供的答案是:这不是一个简单的数据标记或实践中意外的错误,但可能会刺激模型内部结构中的“自然”习惯。简而言之,大型的AI模型就像一个大脑具有无数神经元的大脑,这里隐藏了不同的行为模式。一种无效的调谐,等同于在模型的脑海中意外按下“顽皮的孩子模式”开关。 Openai团队使用了n可解释性技术在模型中找到与这种“不必要”行为高度相关的隐藏功能。您可以将其视为模型“大脑”中的“诀窍”:当激活此因素时,模型开始发疯;如果受到限制,该模型将恢复正常合规性。它表明,模型所学的知识可能具有“隐藏的个性菜单”,其中包含我们想要或不想要的各种Ibang习惯。当训练过程意外增强了错误的“个性”时,AI的“精神状态”非常关注。此外,这意味着“突然的准确性”与通常称为“ AI幻觉”完全不同:据说这是枪的“高级版本”,与整个人格相似。传统的AI幻觉是该模型在发电过程中产生了“内容错误” - 这是胡说八道,但这不是恶意的,因为学生回答了任务测试期间的离子。 “出现未对准”类似于新的“个性模板”,然后悄悄地将此模板用作当天的参考。换句话说,幻觉只是无意识的批评时刻,规则的错误是他们显然对猪的大脑说话。尽管这两个是相关的,但风险水平明显不同:幻觉主要是“错误的错误水平”,可以通过直接词来纠正;虽然准确性是“行为水平”,它涉及认知模型本身趋势的问题,如果无法治愈,则可能是下一次AI事故的根源。 “真正的对齐方式”失去了AI,因为我们发现“ AI变得越来越糟”的风险“ AI正在修复更多”,Openai还提供了最初的响应概念,称为“紧急重新调整”。简而言之,这是为了让AI离开Markasa最后的“更正类”,即使您使用了少量的广告跨越的培训数据,可能没有必要与问题的纳卡地方相关联。该模型从错误的路径中撤回。该实验发现,通过再次使用正确和听话的示例固定模型,该模型也可以“返回正确”,并且以前回答非问题的性能已大大降低。因此,研究人员建议可以在AI解释的帮助下评估该模型的“大脑电路”。例如,本研究中使用的“稀疏自动编码器”工具成功地发现了GPT-4模型中隐藏的“技巧因素”。同样,将来可以为模型安装一个“监视器”,一旦对模型中的某些激活模式进行监控以匹配已知的未对准属性,则将及时发布预警。如果过去,AI培训更像是编程和Dedicatingug,那么现在就像是连续的“起义”。今天,AI培训就像培养A NEW物种。您不仅应该指出其政策,而且要始终照顾出意外变化的风险 - 您认为您正在与边境牧民一起玩,因此请小心玩边境牧民。